 May 28th, 2013 by
May 28th, 2013 by  Lincoln Baxter III
Lincoln Baxter III Announcing PrettyTime :: NLP Natural Date Processing
If you have ever used Google Calendar, Siri, Android Voice Command or other natural language tools, you might be familiar with convenient calendar features and voice calendar control. 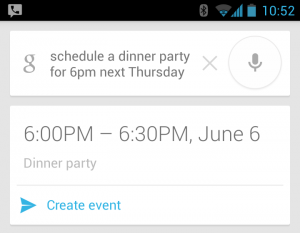 “Schedule a dinner party for six pm, next Thursday,” and The start time for your dinner party conveniently shows up, ready for your finishing touch. But how does this work? Can we use it for our own applications?
“Schedule a dinner party for six pm, next Thursday,” and The start time for your dinner party conveniently shows up, ready for your finishing touch. But how does this work? Can we use it for our own applications?
If you’ve given this a bit of thought, you’ve probably figured out that in order to understand grammar, the nearly infinite possible combinations of words, expressions, numbers, and dialects should require a not insignificant amount of computing power, and a good deal of creativity.
There’s business value, all right.
The ability to coerce our highly variable, fluent speech into a format understandable and usable by computer logic is a complex task with great potential reward. Voice control has long been an aspiration in the field of human computer interaction. Our friends at Google and Siri seem to have come a long way, but these features are mostly unavailable for our use. This highly valuable service is also extremely proprietary and guarded. The value can be seen so clearly that companies are fighting tooth and nail to kill off any potential competition. Google guards its speech recognition service behind miles of servers and proprietary code, opaque to the outside world.
This initial step, the literal translation of spoken words into written text is also only a small fraction of the problem. Not only must words be translated into text, but they must then be parsed and normalized into a grammar that computers can understand and represent in rigid, un-fluent data structures:
Imagine a cardboard packing box that contains a single word or phrase. The box is opaque – you don’t know which word it contains, but there is a white label on the box that displays an identification number, a category, and the identification numbers of several other smaller boxes with which this box must be packaged for shipping. Each smaller box contains other unknown words and phrases, and must be put in the correct order.
Now consider that you are given a set of these boxes, and told, “Without opening any boxes, follow the instructions contained within,” but you don’t understand what’s actually in the boxes, you can’t read them. All you can do is put them in the right order, and ask someone else what they think each box’s contents are (without looking.)
This is effectively what Google voice control and Apple’s Siri (and IBM’s Watson) are doing – building up a set of boxes, each one containing a word, then consulting a reference (some kind of neural network or other AI system) to determine what to do with each box. Ultimately, companies like these are using your words, phrases, and conversations to build lists of marketing data, analyze trends, and figure out how to stay ahead of the curve in their respective business sectors. In the end, a person needs to assign meaning to each of these boxes, but over time, computers should gain a better understanding of what certain boxes mean, and build relationships between them.
So as you can see, there’s a lot more involved than simple transcription; there’s a whole world of logic required in order to put meaning behind these words.
Business value, or business strangle-hold?
Another perspective on this technology actually presents an interesting situation, since the most popular and simple to use solutions are those provided by commercial entities. The few open-source solutions that might put this revolutionary technology into the hands of every-day, science-loving people are more difficult to use, and don’t seem to get the community attention that might help this software really take off. Android and iPhone developers are far more likely to use the built in Android Voice Recognition and Siri technology than they are to use an open-source implementation.
The problem comes when you consider one big thing: Privacy. We are quickly becoming a society where individuals are more than willing to give up their personal information to get a deal, or convenient services. I know first hand; I give up my information for these things every day when I use Gmail and Google Voice; I’m willing to do it, but there are some entities that might not be so willing.
Corporations and businesses may not want their trade secrets and confidential material being parsed, understood, reverse-engineered, and used for marketing analysis – particularly when Google and Apple are known for providing services that compete directly against other online businesses.
Even the untouchable banking industry is being threatened by Google Wallet and Google Glass.
Can open-source keep up?
Several open-source solutions already exist in the Java community, such as the Stanford CoreNLP library and the less recently updated Berkely NLP (a Scala library), but until there is an open voice and language service, there is still the problem of bundling over 250MB of code-libraries into a mobile (or even a server) application, even if you do choose the open-source route. That’s a really big deployment that will slow down even the fastest of application architectures, but there’s opportunity for competition if you can to navigate the various patents that litter this arena like a minefield.
The most likely, outcome, however, is that if you try to compete, you will be sued out of existence, just like the completely legal, non patent-infringing Vlingo: sued by Nuance over invalid patent claims. Patents stifle competition, indeed, but that doesn’t mean you shouldn’t try – there is plenty of room for innovation, and the patent system needs to change.
No matter what happens with patents and competition, the single-most important piece of the puzzle for open-source competition in this market is simplicity. “Simpler is better” is our brand mantra, and with that in mind, we’re planting a foot in this market, too:

Our implementation of natural date and time parsing
Using Natty, a light-weight date and time NLP parser, supporting English, we’ve integrated natural date and time parsing into our PrettyTime: Java Date Formatting library, which is already performing generation of natural language (social) timestamps to be read by humans. PrettyTime converts java.lang.Date objects into human readable forms such as, “10 minutes from now”, or “3 days ago”, and has been internationalized into 31 different languages.
For now, you’ll be able to parse phrases such as, “Let’s get dinner next thursday” and “Easter party 2014” in English only, but hopefully we’ll find an open-source solution for NLP that supports internationalization (at least for dates and times). We will try to drum up enough interest to make this a reality, but since you can’t finish if you don’t start, we’re starting with English.
Fight the corporations, get involved in open-source.
If you are interested in standing up for open-source, then I suggest taking a look at any of the current NLP implementations, Stanford, Berkely, Natty Date and Time, and more. This technology is already changing how we interact with computers, and even if we get past verbal communication, into more neural approaches, we’re going to need to translate between human concepts and computer terms – that’s what this technology is all about.
Posted in OpenSource
So you’re not using JSR 310 yet either, ha?;-D
Not yet 🙂 JDK6 is still the most popular version of Java, so no reason to restrict users yet. Frameworks don’t have the same liberty that end-products do.
Excellent views on natural dat processing Lincoln. This has given me a lot to ponder over.